When you start to work on projects with more than one developer, you suddenly find yourself having to solve what sounds like a very simple problem: Sharing code. At its heart it IS simple, but the reality is that you have to take a disciplined approach. Trying to do this without using a tool designed for the job is a likely path to madness, and it's a bit mad not to do so given that the tools you need are widely available at no cost. Every professional shop, open source project and even many independent individuals makes use of some kind of version control system.
Version control at first feels like a burden. If anything though, it is quite the opposite. Knowing that your old code is out there, ready to be brought back into your project anytime you need it? That's gold. It frees you up to experiment, to explore, to go down paths that you really aren't sure lead anywhere.
So how does one get started? Naturally, as with anything else, it begins with education and access. In this case, you need to determine what you have available to you first. If there's an existing system ready for you to use, you probably want to take advantage of that. If you're a clean slate, you need to get something set up. There are many services out there which provide version control, and it can even be free if you don't have a problem with other people possibly seeing your code. It can also be free if you feel safe just running everything on your own computer or a server you control, although then you may need to install a service and keep it running.
Here are some of the more popular version control systems:
CVS - An old standby, it still works but frankly it's lacking a bit in features more modern systems have.
SVN - More modern and quite functional, I have worked (and continue to do so) in subversion shops for years.
Bitkeeper - This was paid software for years and I've never actually used it myself . It basically came about as an answer to the difficulties Linus Torvalds was having with Linux development.
Git - A slightly more convoluted system than some, but clearly very powerful. This ALSO came about due to Linux development, and apparently due to issues Linus was having with Bitkeeper.
There are others, but these are probably the main ones most of you will be looking at.
I personally use Git (hosted on a service) for code I share on this blog and for my own experimental work. It doesn't cost me anything, and it's nicely integrated with my IntelliJ IDE. It also supports something called a 'gist', which is (as far as I know) a unique way to share a subset of a project in order to request assistance or provide examples.
The basic idea behind version control is the same, no matter what system you use. Your make changes to software on your own computer and make sure that things work the way you want. When you're happy with the code, you check it in to your version control repository. If you are unhappy with the code, or have broken something to the point where fixing it is a major burden, you can just pull the last working copy back down and you're back to a known good starting point.
If multiple programmers are working on a project, things are much the same, except that you will pull the last working copy down a bit more often as you are getting all the changes that others have checked in as well. Things are quite simple as long as two developers aren't working on the same exact files. If they are working on the same files, some manual intervention is likely going to be needed to ensure that changes don't conflict. That last process is called 'merging'.
Merging is a source of difficulty, or it can be, depending on your development practices. I prefer to keep commit changes small and isolated whenever possible. This keeps the differences (deltas) down to manageable levels, and if I've added two new source files rather than modified an existing one, we're not going to run into any problems.
Friday, January 28, 2022
Avoiding the Deadly Quadrant
I saw a video (opens in a new window) recently which illustrated an important concept in a very elegant way.
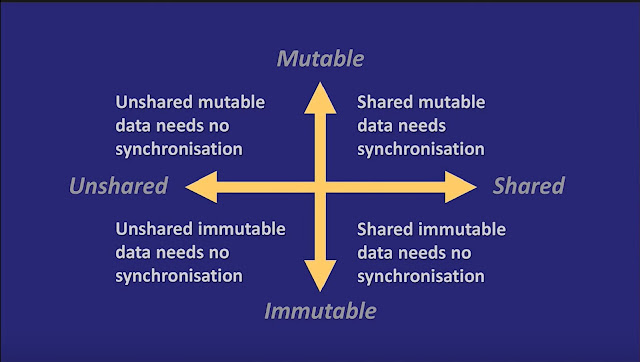
This is important, because in 3/4 of this diagram, your code is inherently safe to run in a multi-threaded environment. There are no synchronization blocks required, there is no need for complicated gatekeeping. And yet, somehow a lot of code winds up with mutable data and synchronization headaches.

This is important, because in 3/4 of this diagram, your code is inherently safe to run in a multi-threaded environment. There are no synchronization blocks required, there is no need for complicated gatekeeping. And yet, somehow a lot of code winds up with mutable data and synchronization headaches.
Applying just a few functional programming principles to your work can go a long way. Parameters should generally be considered inviolate, use return properly and don't try modifying your inputs directly. Prefer constants to variables.
When you kick off a process, you really don't want it randomly reaching out and modifying some kind of global state. If it REALLY needs to send messages home, give it a tool to do so, such as a callback function it can use for that purpose.
Subscribe to:
Posts (Atom)